多云互聯的現實困境與開源SDN之路
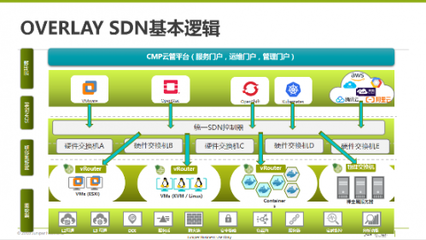
隨著企業數字化轉型的加速,多云策略已成為許多組織的核心選擇。多云互聯在帶來靈活性和成本優化的也面臨著諸多現實困境。網絡連接的復雜性是多云環境的主要挑戰。不同云服務提供商(如AWS、Azure、Google Cloud)使用專有網絡架構,導致跨云通信延遲高、帶寬受限,且配置管理繁瑣。安全性問題突出,數據在公共互聯網中傳輸易受攻擊,而私有連接方案成本高昂。運維管理難度大,缺乏統一的可視化工具,故障排查和性能監控變得復雜。
針對這些困境,開源軟件定義網絡(SDN)技術提供了一條可行的解決路徑。SDN通過將控制平面與數據平面分離,實現了網絡的集中管理和編程控制。在開源SDN框架下,如OpenDaylight、ONOS或Open vSwitch,企業可以構建統一的多云互聯平臺。這些解決方案能夠自動化網絡配置,支持動態帶寬分配,并集成安全策略,從而降低延遲、提升可靠性。例如,通過開源SDN控制器,企業可以輕松實現跨云虛擬網絡覆蓋,確保數據加密傳輸,同時提供實時監控和日志分析。
在軟件技術推廣服務方面,推動開源SDN在多云互聯中的應用需要多方努力。服務提供商應提供定制化咨詢和部署支持,幫助企業評估現有基礎設施并制定遷移計劃。培訓課程和社區資源可以提升技術團隊的能力,加速SDN的落地。結合容器技術(如Kubernetes)和微服務架構,開源SDN能進一步優化應用部署和伸縮性。通過案例分享和最佳實踐推廣,企業可以更直觀地認識到開源SDN在降低成本、提高敏捷性方面的價值。
多云互聯的現實困境雖嚴峻,但開源SDN技術結合專業軟件推廣服務,為企業提供了高效、安全的解決方案。隨著開源生態的成熟和5G等新技術的融合,多云互聯將邁向更智能、自動化的新階段。
如若轉載,請注明出處:http://m.szlianxing8888.cn/product/10.html
更新時間:2026-06-19 07:03:37